The notations are slightly different from the original papers; I have added some more index notations to clarify the meanings of each terms.
Overview
Layer-wise Relevance Propagation (LRP) finds relevance scores for individual features in the input data by decomposing the output predictions of the neural network.
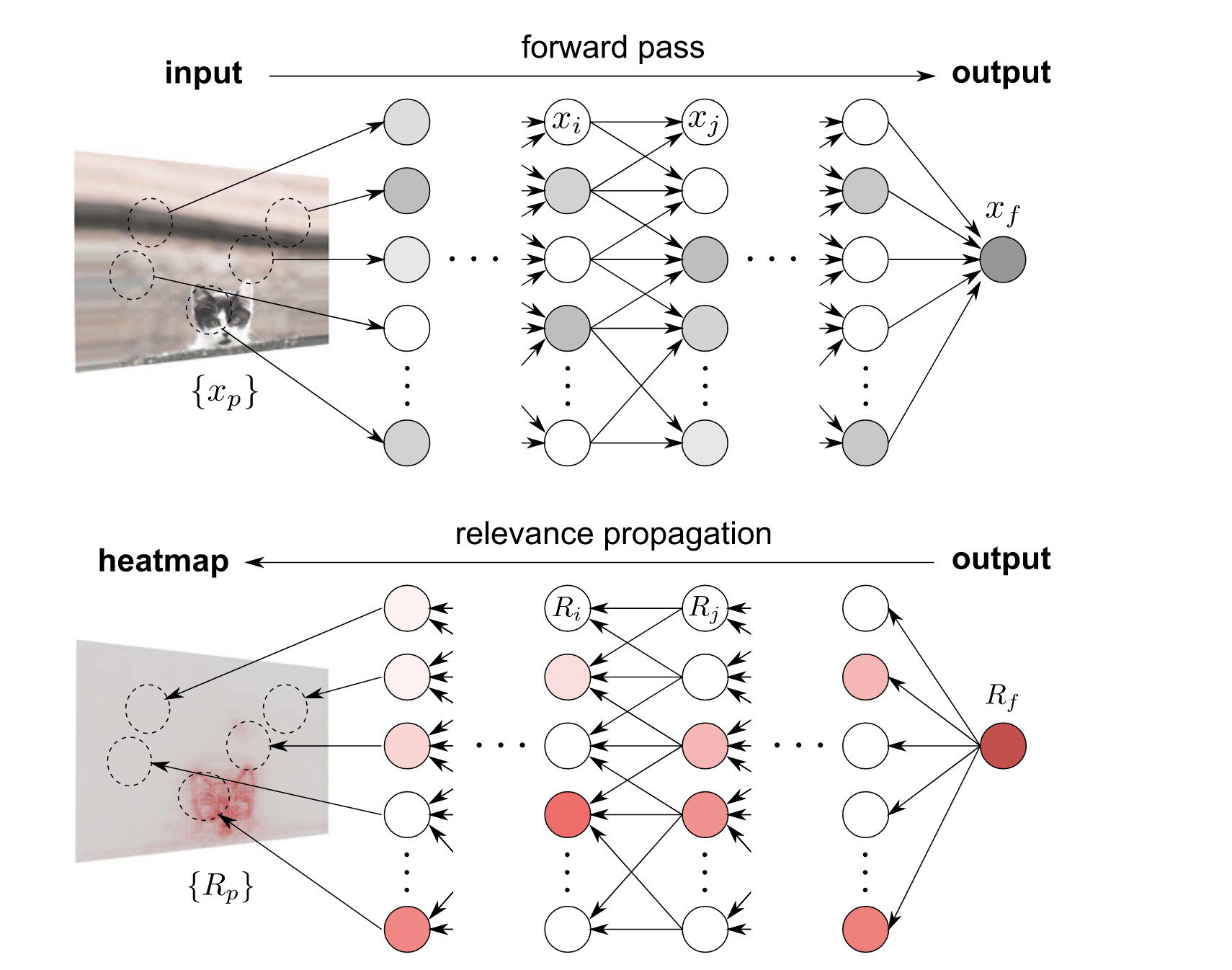
The propagation rule strictly obeys the conservation property: what has been received by a neuron must be redistributed to the lower layer in equal amount. In other words,
for any neuron.
LRP rules
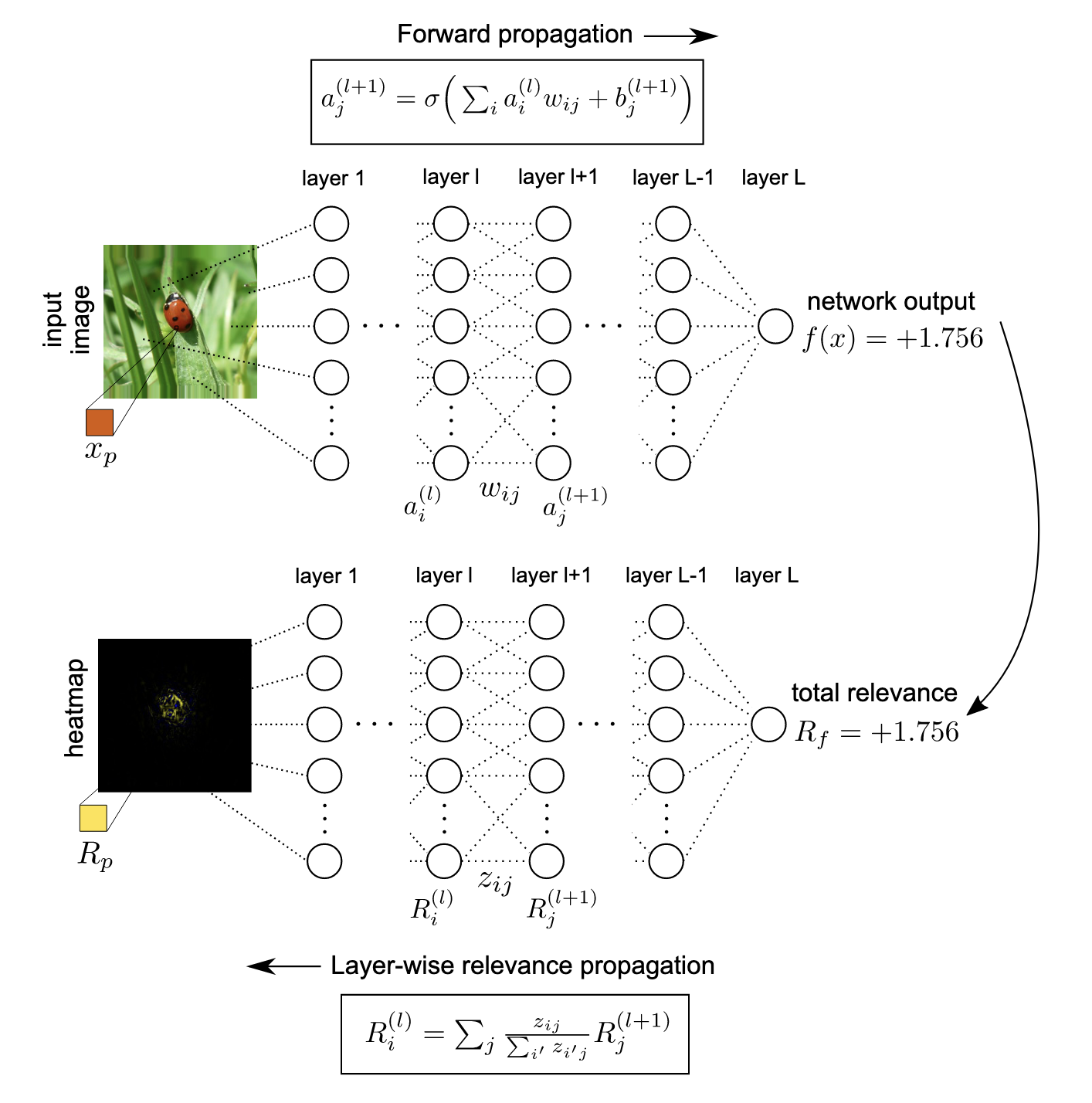
Relevance score propagation at a given layer onto the lower layer follows:
where is the index set of all neurons in the -th layer.
Consequently,
where is the prediction of the neural network for an input .
The quantity indicates how much neuron has contributed to make neuron relevant. There are several possible variants of LRP according to the choice of .
Basic rule (LRP-0)
LRP-0 redistributes relevance score proportionally to the contributions of each input to the neuron activation.
Let be the activation of neuron , and be the weight parameter applied to neuron to neuron of subsequent layer. Then, LRP-0 is defined as
or in other words,
Note that the sum runs over all neurons of the lower layer, including that of the bias term.
Although this rule looks intuitive, a uniform application of LRP-0 to the entire network is empirically shown to be equivalent to gradient input, where the gradients are usually noisy.
Epsilon rule (LRP-)
LRP- adds a small positive term in the denominator.
The term absorbs some relevance when the contributions to the activation of neuron are weak or contradictory (i.e., diminishing the relevance score).
As the term becomes bigger, only the most salient explanation factors survive the absorption, resulting in a less noisy explanation.
Gamma rule (LRP-)
LRP- favours the effect of positive contributions over negative contributions.
Here, and denotes the negative and positive parts of , respectively.
The term quantifies how much the positive contributions are favoured.
The prevalence of positive contributions has a limiting effect on how large positive and negative relevance can grow in the propagation phase, resulting in a more stable explanation.
Deep Taylor decomposition
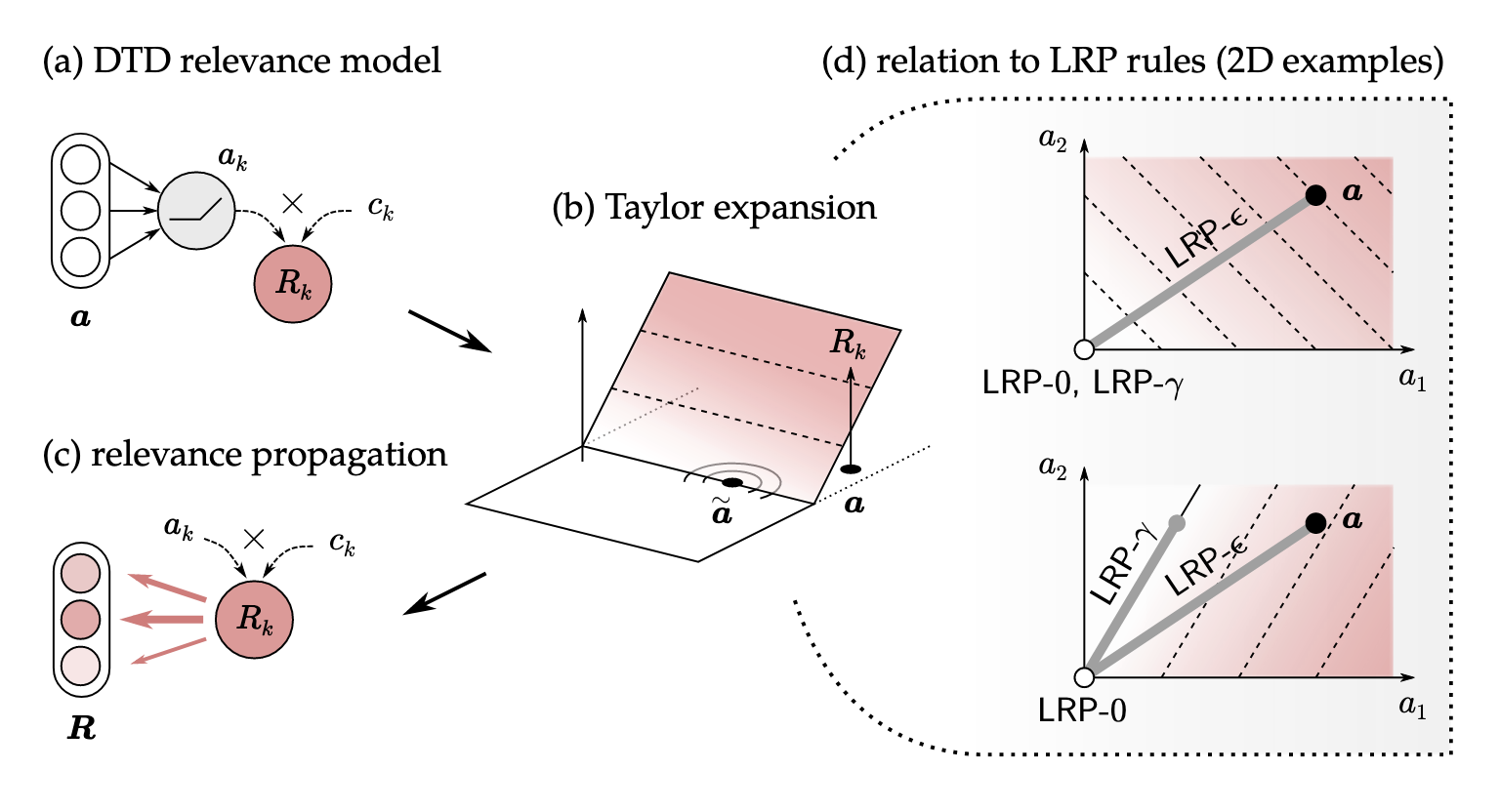
The previous rules can be interpreted with Deep Taylor Decomposition (DTD), which views LRP as a succession of Taylor expansions performed locally at each neuron.
Let denote the vector of lower-level (layer ) activations, and let be some reference point near . Then,
where denotes the error term, which consists of the second and higher order terms of the Taylor expansion that are difficult to compute.
Relevance model
By substituting the relevance function , a closed-form expression can be derived. One popular choice is the modulated ReLU activation:
where is the modulation term set to satisfy .
Then, the Taylor expansion of can be given as
Here, due to the linearity of , (Recall that consists of the second and higher order terms of the Taylor expansion).
Once the reference point is chosen, relevance scores can be easily computed because they only consist of first-order terms.
References
- Bach, S., Binder, A., Montavon, G., Klauschen, F., Müller, K. R., & Samek, W. (2015). On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PloS one, 10(7), e0130140.
- Montavon, G., Binder, A., Lapuschkin, S., Samek, W., & Müller, K. R. (2019). Layer-wise relevance propagation: an overview. Explainable AI: interpreting, explaining and visualizing deep learning, 193-209.
- Kim, S. W., Kang, S. H., Kim, S. J., & Lee, S. (2021). Estimating the phase volume fraction of multi-phase steel via unsupervised deep learning. Scientific Reports, 11(1), 5902.
- Montavon, G., Lapuschkin, S., Binder, A., Samek, W., & Müller, K. R. (2017). Explaining nonlinear classification decisions with deep taylor decomposition. Pattern recognition, 65, 211-222.