Introduction
- Ambiguity arises frequently in open-domain QA, where questions are written during information gathering without knowledge of the answer
- Introduce a new task
AmbigQA, which requries:- Identifying all plausible answers to an open-domain question
- Identifying disambiguated questions to differentiate them
- Construct a new dataset
AmbigNQ- 14,042 annotations on
NQ-openquestions containing diverse types of ambiguity
- 14,042 annotations on
- Introduce the first baseline models that:
- Produce multiple answers to open-domain questions
Task: AmbigQA
Setup

- Input: Prompt question
- Output: List of question-answer pairs
- Each is an equally plausible answer to
- Each is a minimally edited modification of , whose answer is unambiguously
- Subtasks
- Multiple Answer Prediction
- Input: A question
- Output: A set of semantically distinct and equally plausible answers (where is unknown)
- Question Disambiguation
- Input: A question , A set of answers
- Output: Disambiguated questions , where each is a minimal edit of which makes its answer unambiguously and only
- Multiple Answer Prediction
Metrics
-
Goal: Compare a model prediction with QA pairs with a gold reference set with pairs
- Each gold answer is a set of acceptable answer strings, where all are disjoint
-
Correctness score: where is the similarity measure
- Considers:
- The correctness of the answer
- The similarity between the predicted and the reference question
- Considers:
-
Calculate F1 treating as measures of correctness
- Choices of similarity measure :
- : Always yields 1
- : Computes BLEU scores
- : Computes F1 score from unigram diffs
- Prompt question: “Who made the play the crucible?”
- Gold edit: “Who wrote the play the crucible?” →
- Predicted edit: “Who made the play the crucible in 2012?” →
- Choices of similarity measure :
Data: AmbigNQ
Collection
- Used prompt questions from
NQ-open, English Wikipedia as the evidence corpus - Constructed via crowdsourcing
- Two stage pipeline: generation and validation
Generation
- Given a prompt question and a Google Search API restricted to English Wikipedia
- Find all plausible answers to the question
- For some questions containing temporal deixis, remove time-dependence by rewriting the prompt question
Validation
- Review the annotations provided by multiple generators
- Mark each generator’s annotations as correct / incorrect
- Provide a new set of QA pairs by combining the valid ones from each generator
- Access to Wikipedia and the pages that generators viewed
- Skipped when annotated answers from all generators exactly match
Quality Control
- Highly qualified workers
Analysis
Types of Ambiguity

Model
- Input: Prompt question
- Predict: Answers
- Generate: Corresponding questions , conditioning on , the answers , and the evidence (top) passages
Multiple Answer Prediction: SpanSeqGen
- Follows DPR
- Retrieve 100 passages with a BERT-based bi-encoder
- Rerank the passages using a BERT-based cross-encoder
- Sequentially generates distinct answers token-by-token, conditioned on the concatenation of and the top passages in order up to 1024 tokens using a BART-based seq2seq model
Question Disambiguation
- BART-based model
- Generates each question conditioning on the concatenation of , the target answer , other answers , and the top passages as used by SpanSeqGen
- Pretrain on
NQ-opento generate questions given an answer and passage - Finetune on
AmbigNQ
Co-training with Weak Supervision
- Treats
NQ-openannotations as weak supervision - Learns to discover potential ambiguity in the data

Experiments
Baselines
Disambig-first
- Feed the prompt question into a BERT-based binary classifier to determine whether it is ambiguous
- If so, pass it into a BART-based model which generates a sequence of disambiguated questions
- Otherwise consider only
- Feed each into SOTA model on
NQ-opento produce its answer
Thresholding + QD
- DPR model with thresholding for multiple answer prediction
- DPR outputs a likelihood score for each span
- Obtain by taking valid spans with likelihood larger than a hyperparameter
- Training process same as
SpanSeqGen
Results
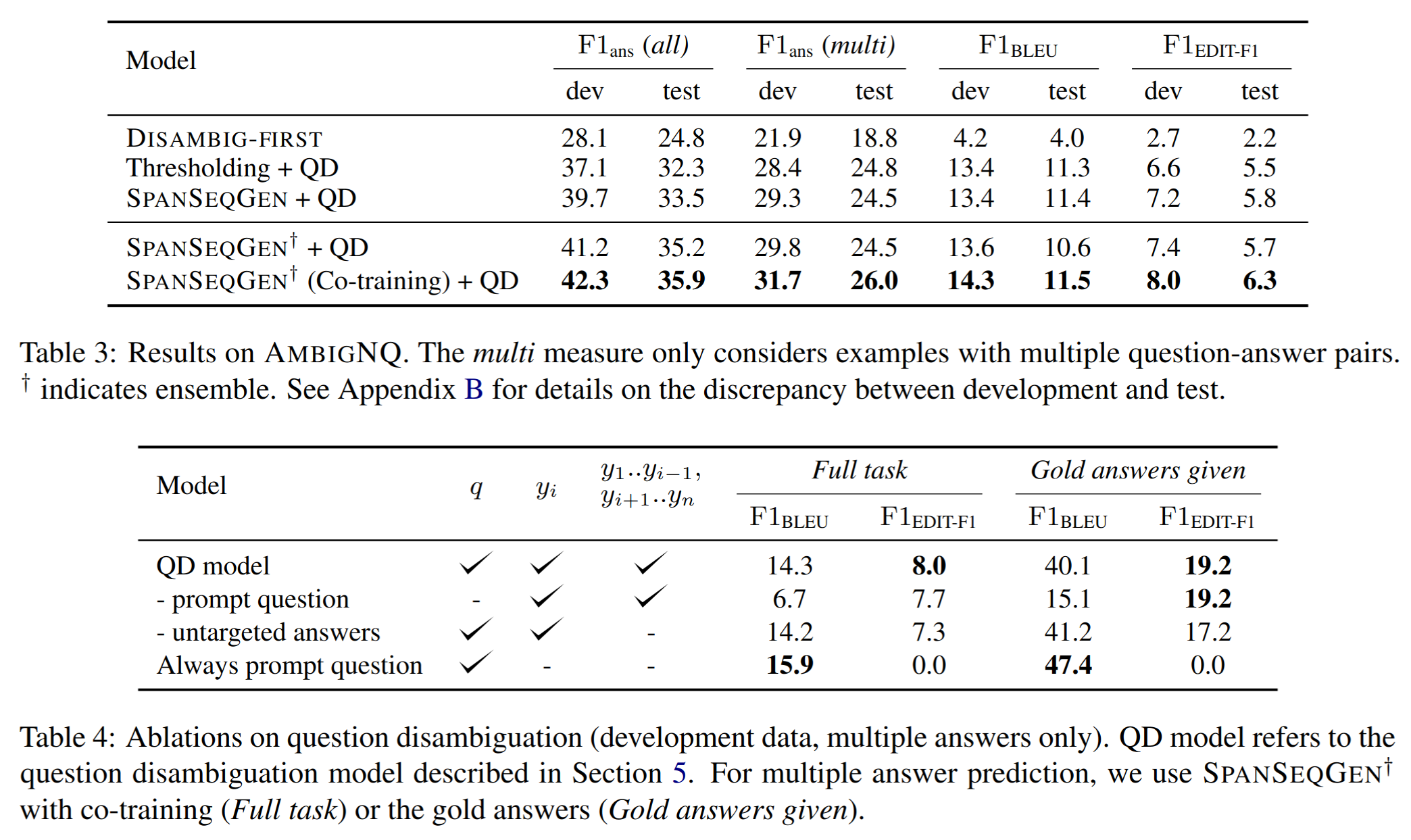
Disambig-firstis significantly worse than other models- Ambiguity classification accuracy (67%) is close to the majority baseline (60%)
- When the model rewrites an ambiguous question, its rewrites look reasonable but do not match the facts
- Reading evidence documents is crucial for identifying and characterising ambiguities
SpanSeqGen + QDoutperformsThresholding + QD, but with little difference- Thresholding may be a surprisingly effective baseline for outputting multiple answers
- Maximising likelihood in a seq2seq model (
SpanSeqGen) may not produce well-calibrated results- Suffer from variation in the length of the output sequence
- Substantial difference in performance between development and test overall
- Likely due to distributional differences in the original questions in
NQ-open
- Likely due to distributional differences in the original questions in
- Ensemble trained with co-training method achieves the best performance on all metrics
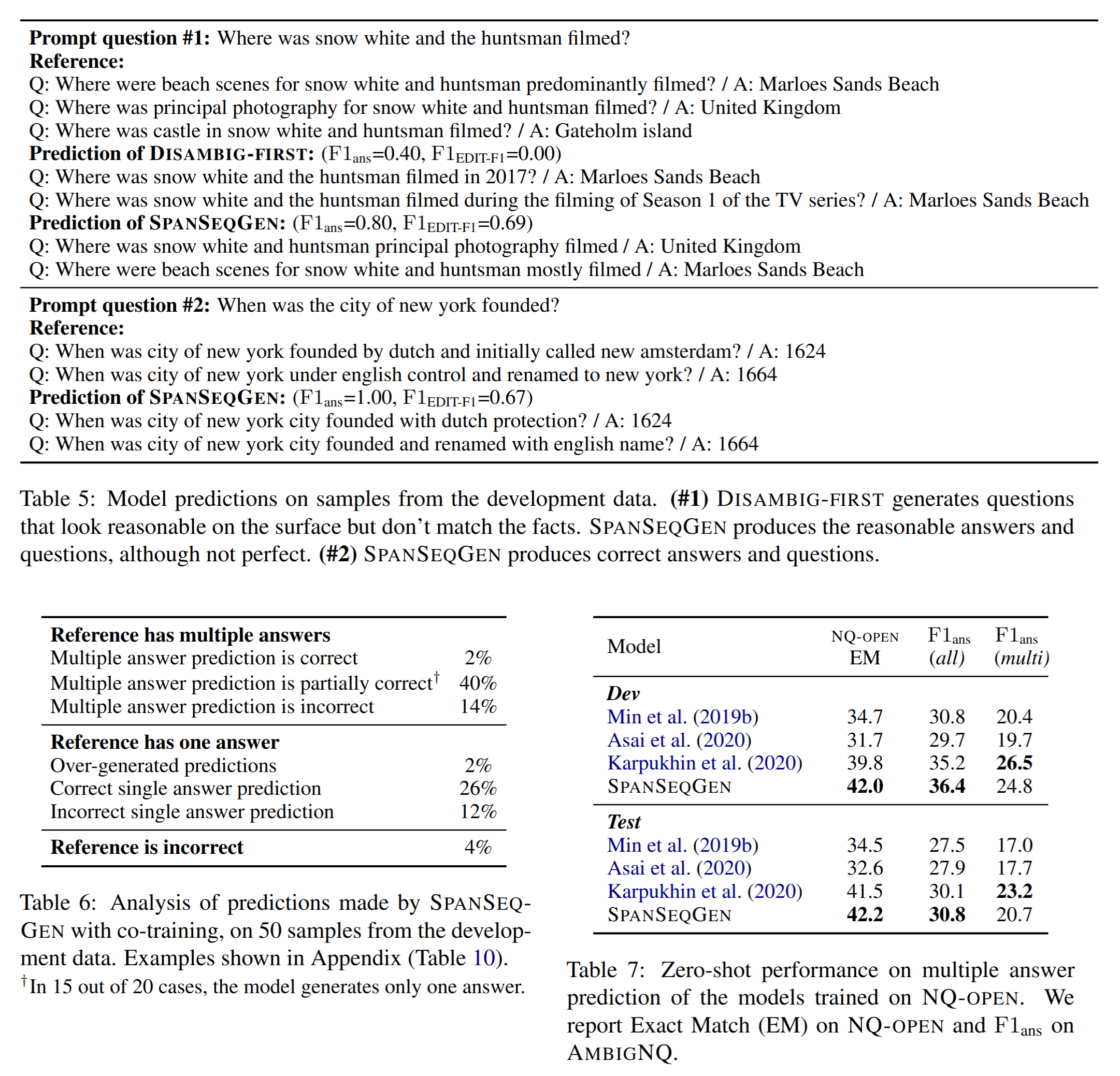
Ablation Study
- Simply copying the prompt question gives high F1-BLEU score
- Justifies using F1-EDIT-F1 to evaluate semantic differences from the prompt question
- QD model conditioned on all available context is better than other variants
- Overall low performance, even given the gold answers
- Maximising the likelihood of the output sequence can miss the importance of edits to the prompt question
- QD model may miss the information that is most important to differentiate one answer from the others
- Lack of annotated data, especially for question disambiguation
- Metric may miss edits that are semantically correct, but phrased differently
- Maximising the likelihood of the output sequence can miss the importance of edits to the prompt question
Zero-shot Results
- System predicts multiple distinct answers without using
AmbigNQtraining data
Error Analysis
- When there are multiple reference answers, the model rarely gets all correct answers, although often generates a subset of them
- Accuracy on examples with a single answer is quite high, higher than SOTA levels on
NQ-openNQ-openmay substantially underestimate performance due to the prevalence of unmarked ambiguity
- Recall of multiple answers is one of the primary challenges in
AmbigQA
Conclusion & Future Work
- Explicitly modelling ambiguity over events and entities
- Open-ended approaches on top of
AmbigQA:- Applying the approach to QA over structured data
- Handling questions with no answer or ill-formed questions that require inferring and satisfying more complex ambiguous information needs
- More carefully evaluating usefulness to end users
References
- Min, S., Michael, J., Hajishirzi, H., & Zettlemoyer, L. (2020). AMBIGQA: Answering ambiguous open-domain questions. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2004.10645
- Karpukhin, V., Oğuz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., & Yih, W. (2020). Dense passage retrieval for Open-Domain question answering. arXiv (Cornell University). https://arxiv.org/pdf/2004.04906.pdf