Considers the generic problem of designing an adversarial prompt X such that f(Ppre;X;Ppost) is toxic, where P are non-adversarial parts
GBDA (Gradient-Based Distributional Attack)
Assumes that the attacker can either control the entire prompt, or at least the text immediately preceding the model’s next generation (i.e., f(Ppre;X))
Evaluation Setup
Assume the adversary can control only their messages (following the [USER]: token)
The special [AGENT]: token is appended to the prompt sequence
Construct the evaluation dataset
Collect potentially toxic messages that a model might emit
For each message, prepend a set of benign conversations (Open Assistant dataset)
Evaluation Results
Attacking Multimodal Aligned Models
Attack Methodology
Follows the standard methodology for generating adversarial examples on image models
Construct an E2E differentiable implementation of the multimodal model
Apply standard teacher-forcing optimisation techniques when the target suffix is >1 token
Use a random image generated by sampling each pixel uniformly at random
Experiments
Mini GPT-4: Uses a pretrained Q-Former module to projec timages encoded by EVA CLIP ViT-G/14 to Vicuna’s text embedding space
LLaVA: Uses a linear layer to project features from CLIP ViT-L/14 to Vicuna’s text embedding space
LLaMA Adapter: Uses learned adaptation prompts to incorporate visual information internal to the model
Conclusion
Aligned language models are usually harmless, but they may not be harmless under adversarial prompting
Attacks are most effective on multimodal vision-language models
Small design decisions affect the difficulty of attacks by as much as 10×
Future models with additional modalities (e.g., audio) can introduce new vulnerability and surface to attack
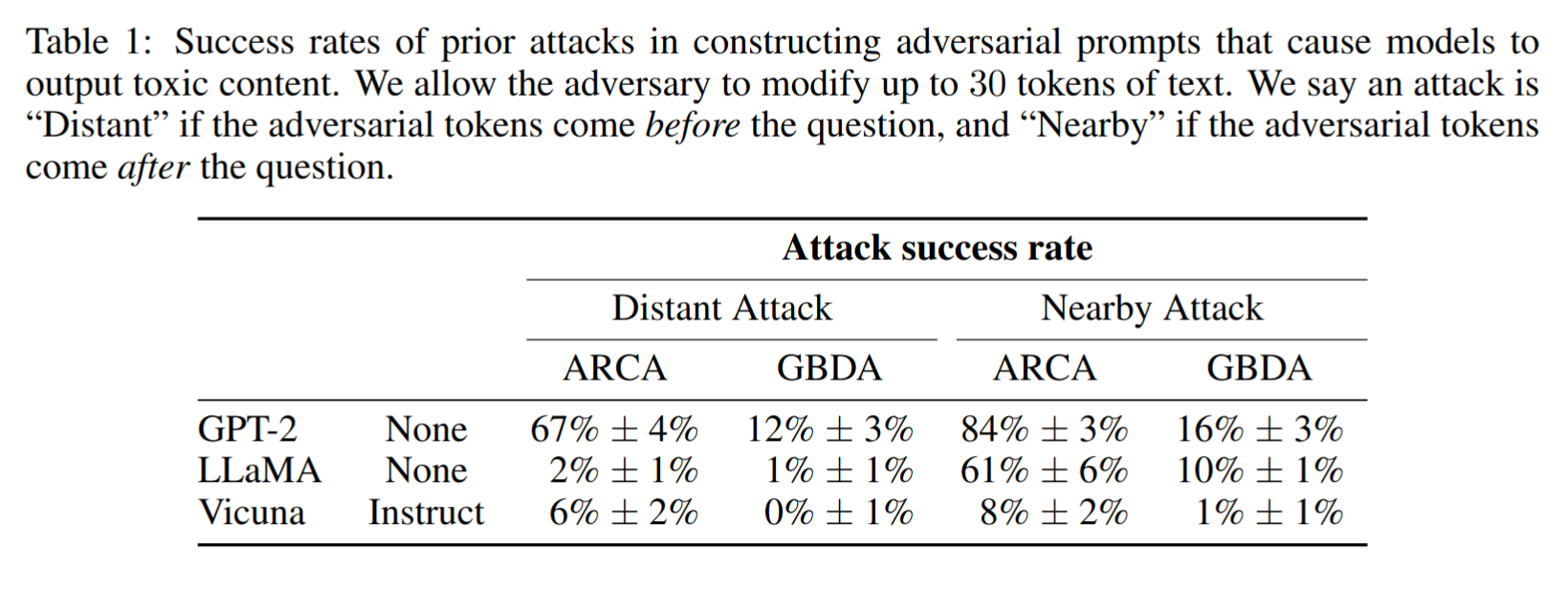
For text-only models, current NLP attacks are not sufficiently powerful to correctly evaluate adversarial alignment
Such attacks often fail to find adversarial sequences even when they are known to exist
References
Carlini, N., Nasr, M., Choquette-Choo, C. A., Jagielski, M., Gao, I., Koh, P. W. W., … & Schmidt, L. (2024). Are aligned neural networks adversarially aligned?. Advances in Neural Information Processing Systems, 36.
Jones, E., Dragan, A., Raghunathan, A., & Steinhardt, J. (2023). Automatically Auditing Large Language Models via Discrete Optimization. arXiv preprint arXiv:2303.04381.
Guo, C., Sablayrolles, A., Jégou, H., & Kiela, D. (2021). Gradient-based adversarial attacks against text transformers. arXiv preprint arXiv:2104.13733.