Challenges with Naive RAG
Bad Retrieval
- Low precision: Not all retrieved chunks are relevant
- Hallucination + Lost-in-the-middle problems
- Low recall: Not all relevant chunks are retrieved
- Lacks enough context for LLM to synthesise an answer
- Outdated information: The data is redundant or out of date
Bad Response Generation
- Hallucination: Makes up an answer not in the context
- Irrelevance: Does not answer the question
- Toxicity / Bias: Harmful / offensive answer
Evaluation
We need a way to measure performance to improve the performance.
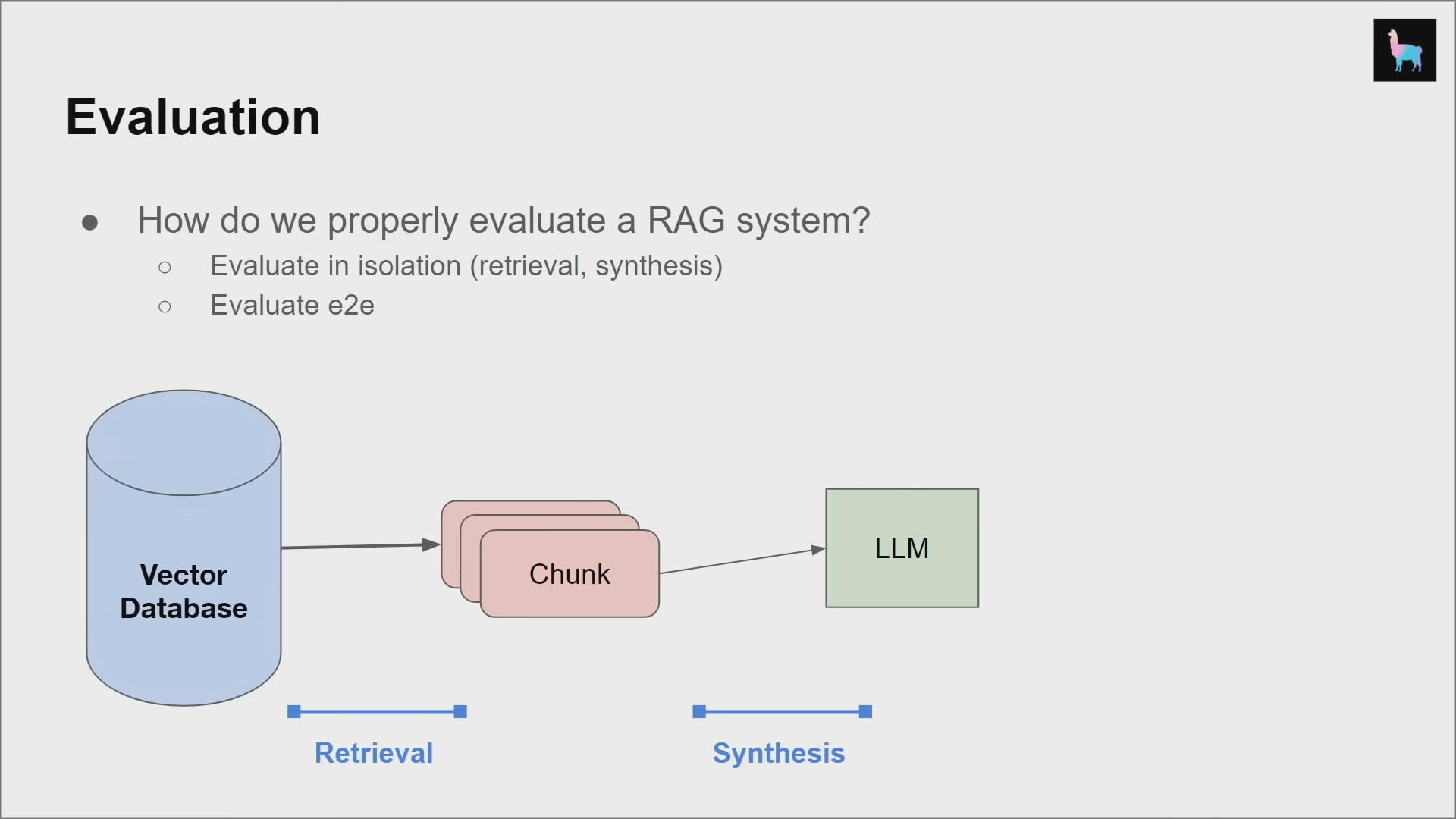
Retrieval
Evaluate the quality of retrieved chunks given a user query.
- Create a dataset
- Input: query
- Output: Ground-truth documents relevant to the query
- Run retriever over dataset
- Measure ranking metrics
- Success rate / Hit-rate
- MRR
- NDCG
End-to-End (E2E)
Evaluate the final generate response given a user query
- Create a dataset
- Input: query
- (Optional) Output: Ground-truth answer
- Run full RAG pipeline
- Collect evaluation metrics
- Label-free evals: Faithfulness, relevancy, adherence to guidelines, toxicity
- With-label evals: Correctness
Optimising RAG Systems
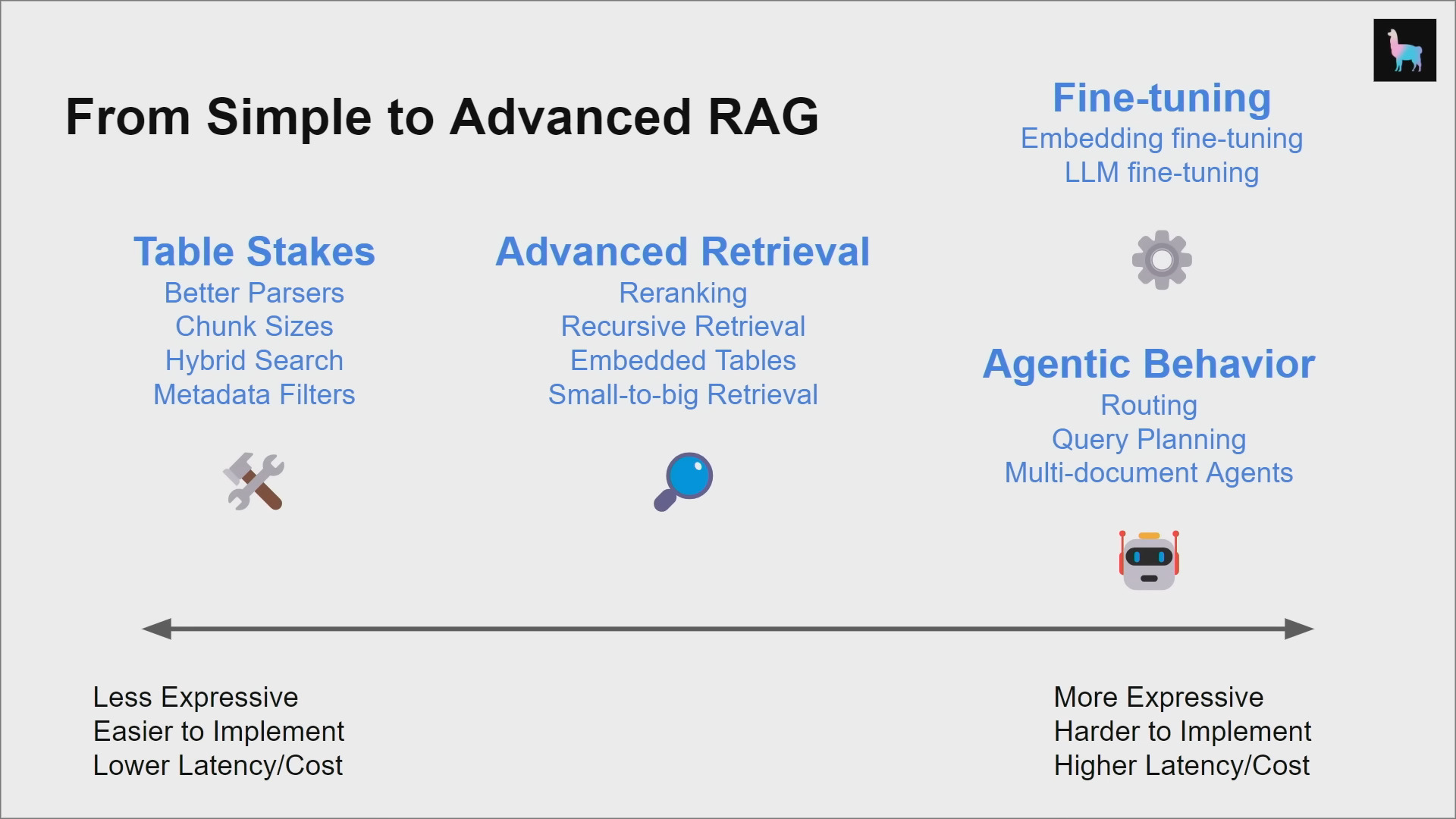
Table Stakes
Chunk Sizes
- Tuning the chunk size can have impacts on performance
- Not obvious that more retrieved tokens lead to higher performance
- Reranking (shuffling context order) isn’t always beneficial
- Due to lost-in-the-middle problems: Information in the middle of the LLM context window tends to get lost, while information at the end are well remembered
Metadata Filtering
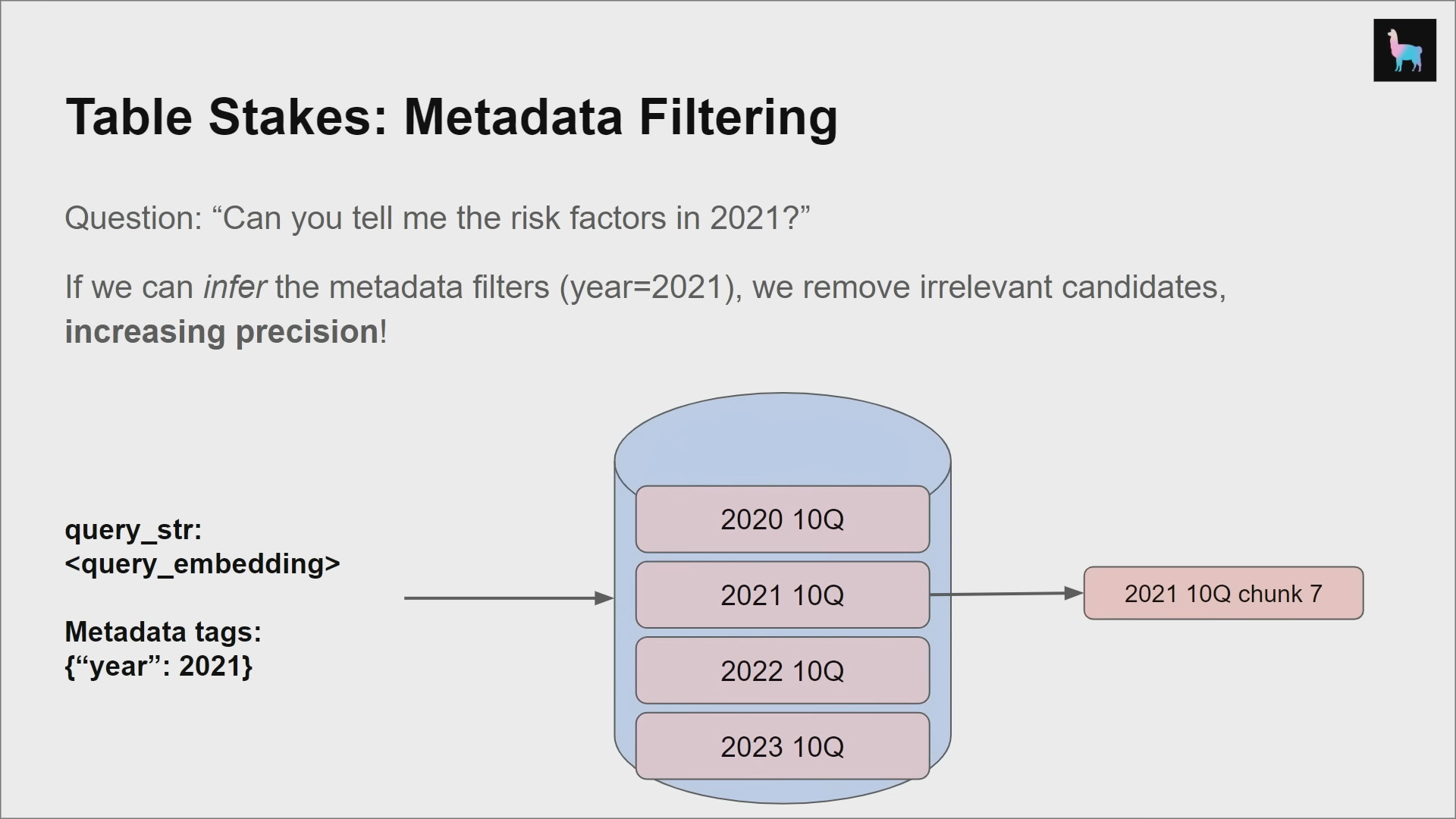
- Metadata: Context you can inject into each text chunk
- e.g., Page number, document title, summary of adjacent chunks, questions that chunk can answer (reverse HyDE)
- Benefits
- Can help retrieval
- Can augment response quality
- Integrates with VectorDB metadata filters
Advanced Retrieval
Small-to-Big

 Image Source: LlamaIndex
Image Source: LlamaIndex
- Intuition: Embedding a big text chunk feels suboptimal.
- Solutions
- Embed a text at the sentence-level, then expand that window during synthesis (Sentence window retrieval)
- Embed a smaller reference (e.g., smaller chunks, summaries, metadata) to the parent chunk, and use the parent chunk for synthesis
Structured Retrieval
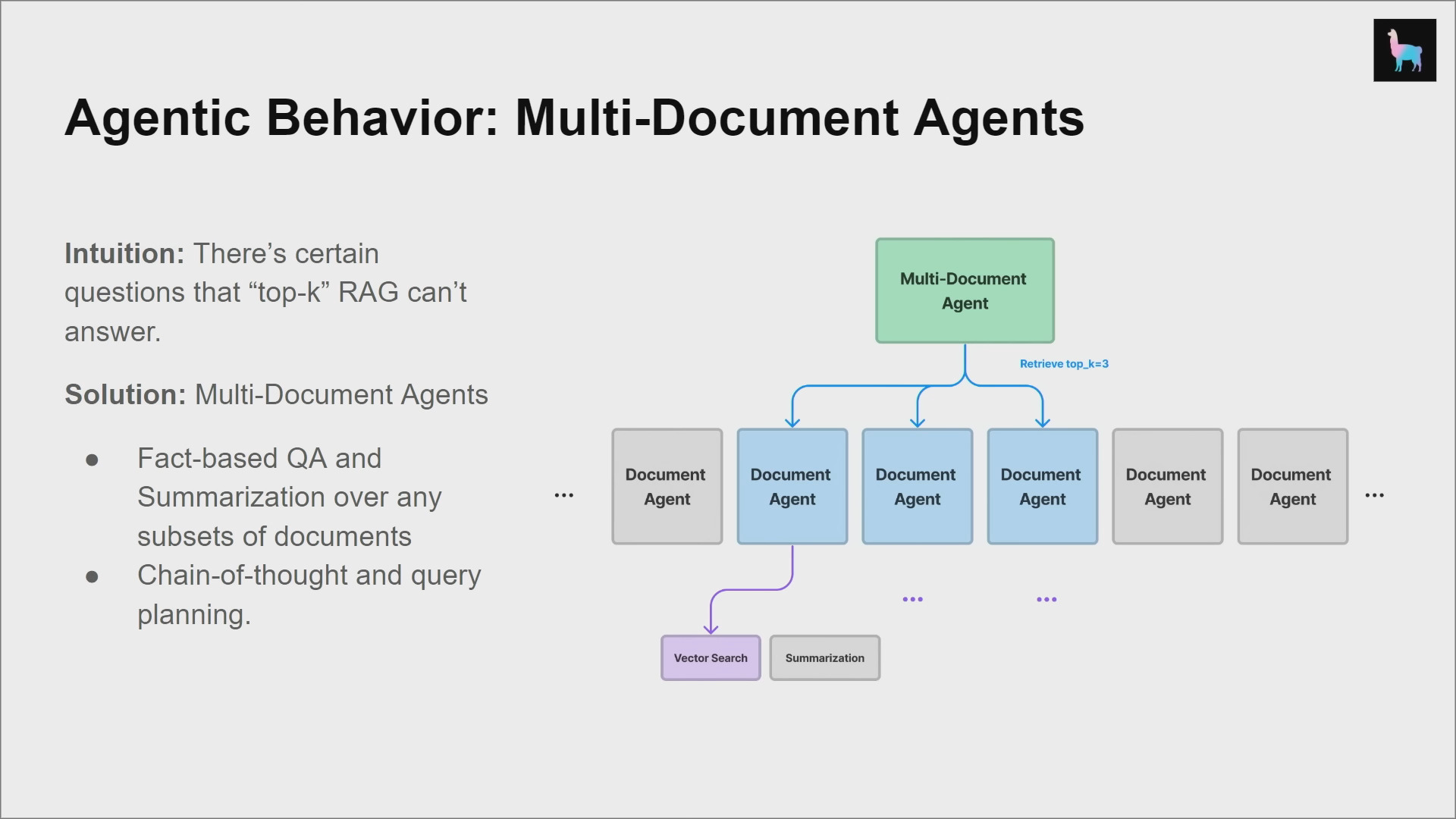
Agentic Behaviour
Multi-Document Agents
Fine-Tuning
Embedding Model
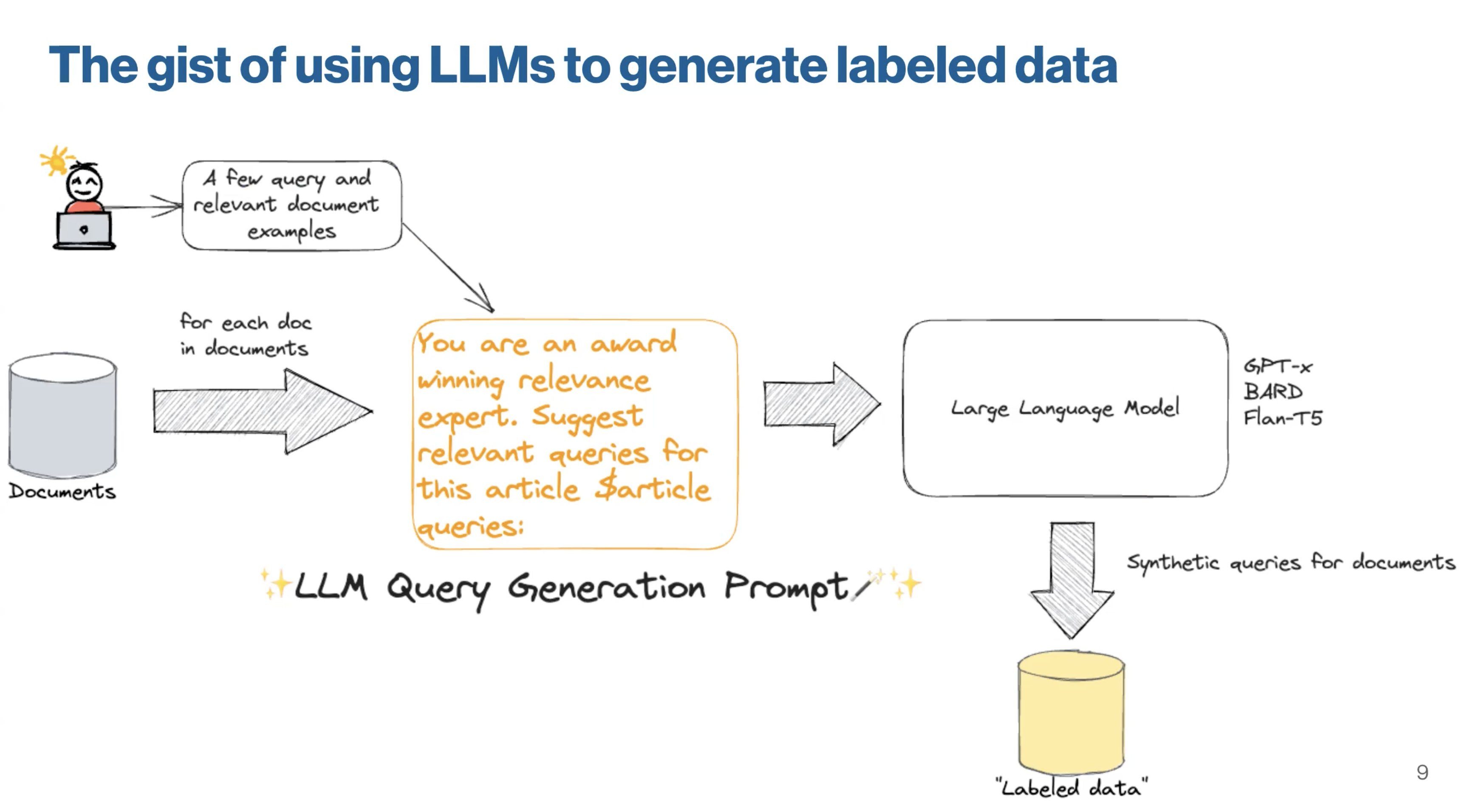 Image Source: Jo Kristian Bergum,
Image Source: Jo Kristian Bergum, vespa.ai
- Intuition: Embedding representations are not optimised over the custom dataset
- Solution: Generate a synthetic query dataset from raw text chunks using LLMs, and use this synthetic dataset to finetune an embedding model
LLM
- Intuition: Weaker LLMs are relatively worse at response synthesis, reasoning, structured oututs, etc.
- Solution: Generate a synthetic dataset from raw chunks using strong LLMs, and use the synthetic dataset to finetune the LLM
References
- AI Engineer. (2023, November 15). Building Production-Ready RAG Applications: Jerry Liu. YouTube. https://www.youtube.com/watch?v=TRjq7t2Ms5I
- Building performant RAG Applications for Production - LLAMAIndex 0.9.47. (n.d.). https://docs.llamaindex.ai/en/stable/optimizing/production_rag.html