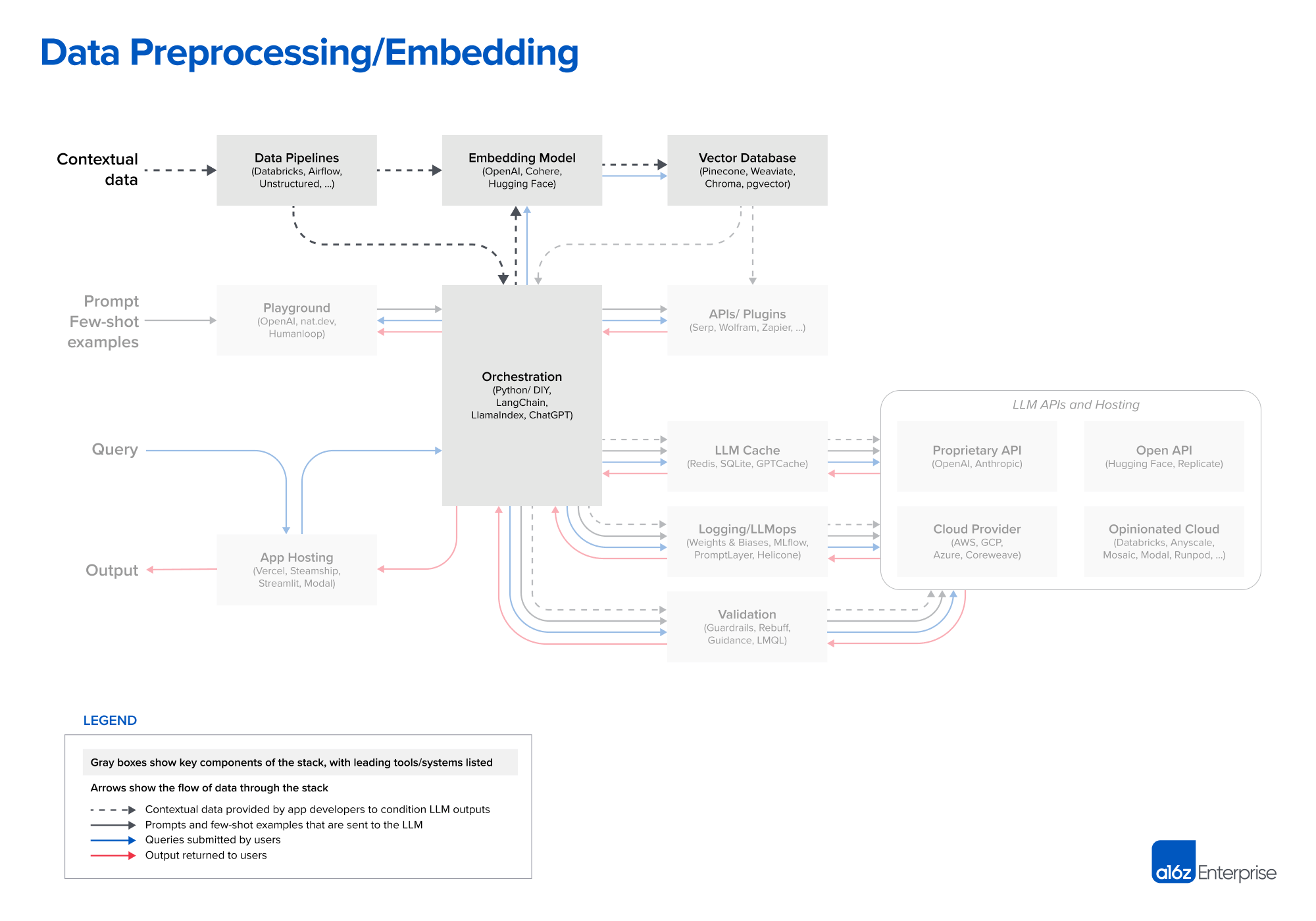
Data are broken into chunks, passed through an embedding model, then stored in a vector DB.
Stack
Data Pipeline
Traditional ETL tools (e.g., Databricks, Airflow)
Document loaders built into orchestration frameworks (e.g., LangChain, LlamaIndex)
Embeddings
OpenAI API (text-embedding-ada-002)
Easy to use, gives reasonably good results, becoming increasingly cheap
Cohere
Focused more on embeddings, better performance in certain scenarios
HuggingFace Sentence Transformers (open source)
Vector Database
Cloud-hosted (e.g., Pinecone)
Easy to get started with, good performance at scale, SSO, uptime SLA
Open source systems (e.g., Weaviate, Vespa, Qdrant)
Excellent single-node performance, can be tailored for specific applications
Local vector management libraries (e.g., Chroma, FAISS)
Great developer experience, easy to spin up for small apps and experiments
Don’t necessarily substitute for a full database at scale
OLTP extensions (e.g., pgvector)
Good solution for enterprises who buy most of their data infrastructure from a single cloud provider
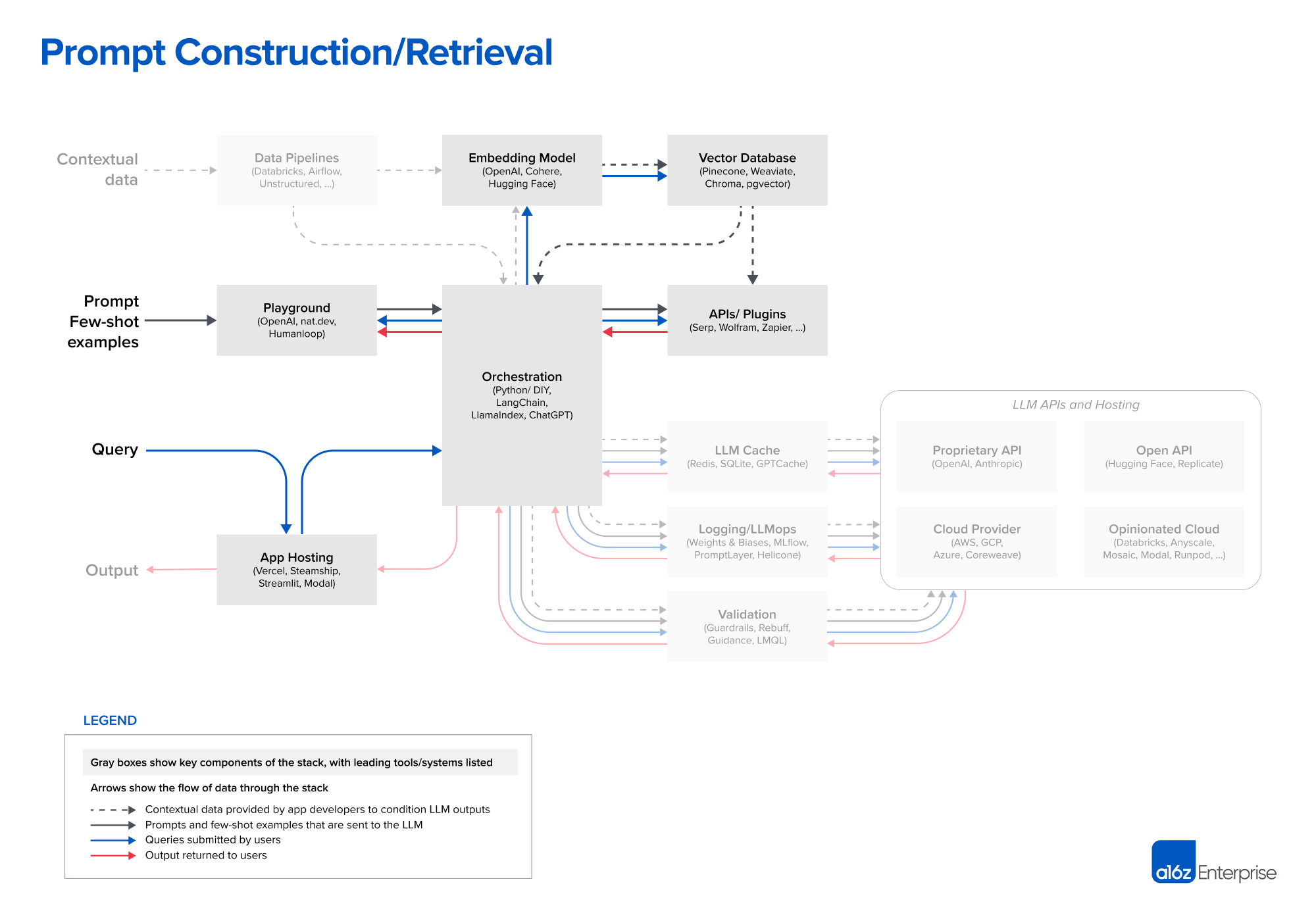
Prompt Construction / Retrieval
Given a query from a user, the application constructs a series of prompts to submit to the LM.
Prompt typically combines a prompt template hard-coded by the developer.
Stack
Orchestration: Abstract away many of the details of prompt chaining (e.g., interacting with external APIs, retrieving contextual data from vector DBs, maintaining memory across multiple LLM calls)
LangChain
LlamaIndex
ChatGPT
Can be considered a sustitute solution
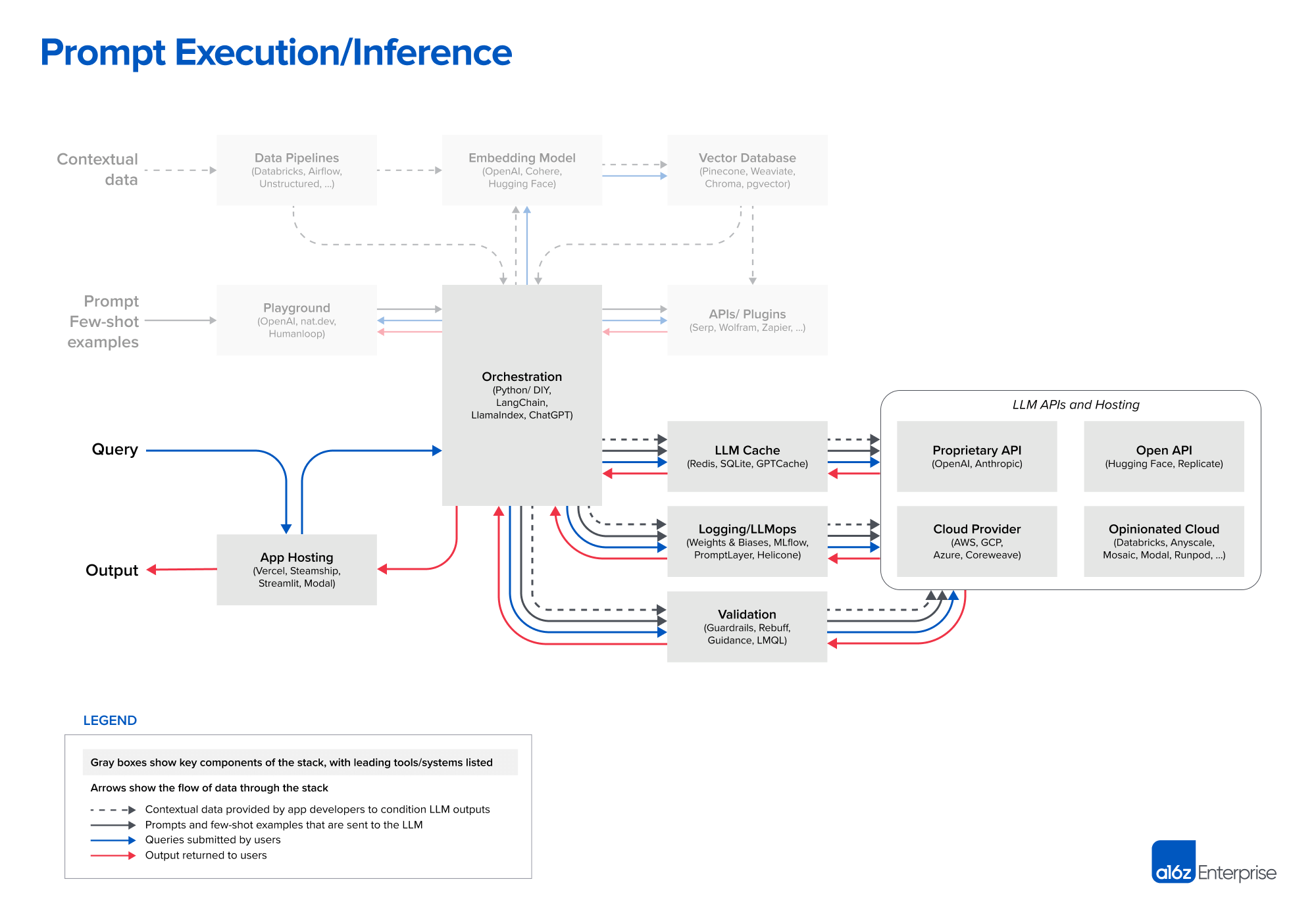
Prompt Execution / Inference
Compiled prompts are submitted to a pretrained LLM for inference.
Either proprietary model APIs, or open-source / self-trained models
Stack
LLM
OpenAI API
gpt-4 / gpt-4-32k: Best-case scenario for app performance, requires no fine-tuning or self-hosting
gpt-3.5-turbo: ~50x cheaper and significantly faster than GPT-4.
Other proprietary vendors
Anthropic’s Claude: Fast inference, GPT-3.5-level accuracy, more customisation options, up to 100k context window (accuracy degrades with the input length)
Open source models
Effective in high-volume B2C use cases (e.g., search / chat) where there’s wide variance in query complexity and a need to serve free users cheaply
Makes the most sense in conjunction with fine-tuning base models