Coverts a variety of lexical, syntactic, and pragmatic ambiguities, and sentences which can be plausibly read as conveying one of multiple different messages
Characterising ambiguity requires a choice of meaning representation to distinguish between possible interpretations (enumerating can be tricky or impractical)
Adopt a functional approach
Characterise ambiguity in the premise and/or hypothesis by its effect on entailment relations
Design a suite of tests based on AmbiEnt to investigate the extent to which understanding of ambiguity is acquired during pretraining of LLMs
Investigate whether LMs can be finetuned on existing NLI data for the less demanding task of ambiguity recognition (w/o explicit disambiguation)
AmbiEnt
Curated Examples
Handwritten or sourced from existing NLI datasets and linguistics textbooks
DistNLI, ImpPres, NLI Diagnostics, MNLI, WaNLI
Generated Examples
Automatically identify groups of premise-hypothesis pairs that share a reasoning pattern
Use WaNLI as source of examples
Each group contains
A randomly chosen example on which its two annotators disagreed
Its 4 nearest neighbours (according to the final-layer embedding of a WaNLI-trained NLI model)
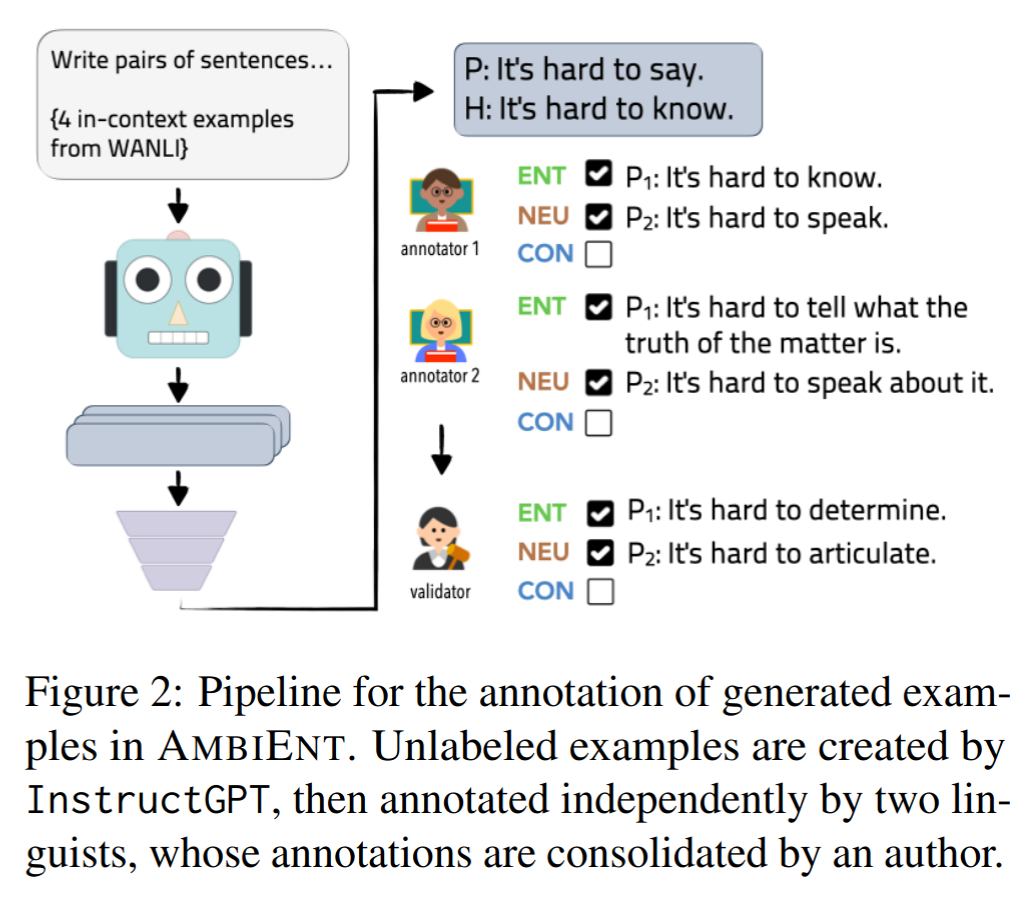
Format each group into a prompt with instruction, sample 5 continuations from InstructGPT
Annotation and Validation
Examples from InstructGPT consist of unlabelled premise-hypothesis pairs
Annotation phase
37 university-level linguistics students
Select a set of labels for each examples
Provide a disambiguating rewrite for each one if more than one label is chosen
Discard offensive or low-quality examples
Validation phasse
Performed by subset of the authors
Review two sets of annotations to revise
Aggregate them into a single coherent annotation
Agreement
Four validators annotate a subset of 50 examples in common to calculate inter-annotator agreement
Analysis
Analysis to understand how annotators behave on ambiguous input (under the traditional 3-way annotation scheme for NLI)
Setup
Crowdworkers review ambiguous examples in AmbiEnt
Task is split into three steps
Annotation of ambiguous example
Follows the traditional NLI labelling setup
Recognition of disambiguities
The ambiguous sentence of the example is given for consideration
Given 3 candidate interpretations (2 disambiguations and 1 distractor), indicate whether each sentence is a possible interpretation of the ambiguous sentence
Annotation of disambiguated examples
3 new NLI examples are obtained by substituting the ambiguous sentnce of the original excample with each candidate interpretation from step 2
Select a single NLI label for each new example
Evaluating Pretrained Language Models
Evaluate if LMs can:
Directly generate relevant disambiguations
Recognise the validity of plausible interpretations
Model open-ended continuations reflecting different interpretations
Ambiguous instances from AmbiEnt
Generating Disambiguities
Whether LMs can learn in-context to directly generate disambiguations and corresponding labels
Human: Same setup as the previous crowdworker experiment (w/o step 1)
Recognising Disambiguities
Focus on the ambiguous sentences alone
Model prediction: token with the greater logit between True and False
Executed zero-shot
Modelling Interpretation-Specific Continuations
Whether LMs implicitly model different interpretations in their distributions of text continuations
Obtain continuations for each interpretation, and quantify how surprised the LM is to see them
Sample 100 continuations c∼p(⋅∣di) conditioned on each disambiguation di as context
Compare the likelihood of c under ambiguous sentence a vs. the corresponding disambiguation di:
logp(c∣di)−logp(c∣a)
This is an unbiased estimate of the KL divergence between p(⋅∣di) and p(⋅∣a)
Expect the LM to model continuations from disambiguations di better than those from the distractor d~:
DKL(p(⋅∣d~)∣∣p(⋅∣a))>DKL(p(⋅∣di)∣∣p(⋅∣a))
KL ranking accuracy: The fraction for which this is true
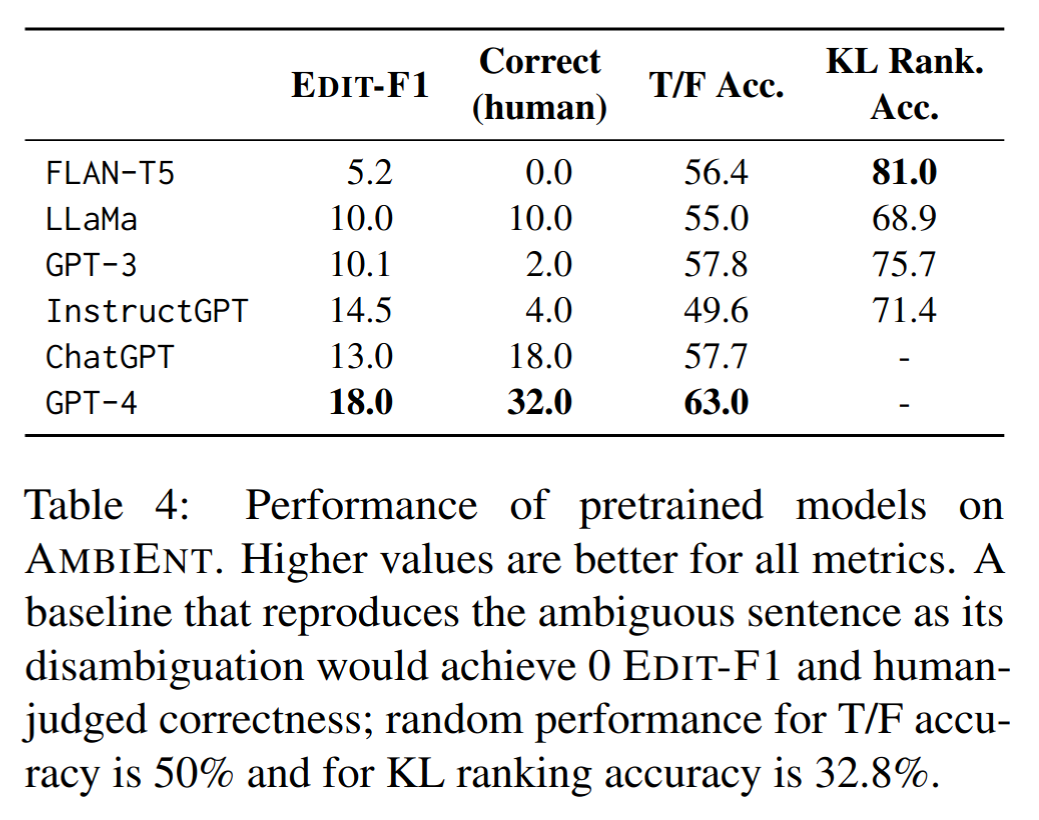
Results
References
Liu, A., Wu, Z., Michael, J., Suhr, A., West, P., Koller, A., Swayamdipta, S., Smith, N. A., & Choi, Y. (2023). We’re Afraid Language Models Aren’t Modeling Ambiguity. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2304.14399